
Let’s talk indexes
Like all OutSystems developers, I have been working with entities and their indexes since day one. I knew they had tradeoffs and that using them correctly sometimes would make a slow query run smooth instead. However, one day someone asked me, “what is an index?” for which I had no good answer, so I decided to investigate. Now, I would like to share with you what I have learned.
What are Indexes?
Databases handle thousands or even millions of records, and they need to be able to return results in milliseconds. Thus, it was imperative to optimize data fetching: indexes. An index is a sorted representation of the data and a set of pointers to the whole record. Taking a book index as an example, we have our data sorted by topics and then page numbers where we can find the information about them.
For the databases to optimize the search times, they usually use a binary search generalization, allowing for greater scalability. The most common type of structure used for this is a B-Tree (or balanced tree).
You can read more on binary search here: Binary search (article) | Algorithms | Khan Academy.
B-Tree
A B-Tree is a set of nodes with keys and pointers. When looking for a specific record (index seek), we start at the root node and check between which keys our value is. This will result in a pointer for the next node. Additionally, the nodes point towards the previous and the next node, helping when searching for a range.
When we reach the leaf nodes, we can have either a pointer to where the data is stored or the data itself (a clustered index).
This search process scales very efficiently (O(log n)), making it perfect for searches in large datasets.
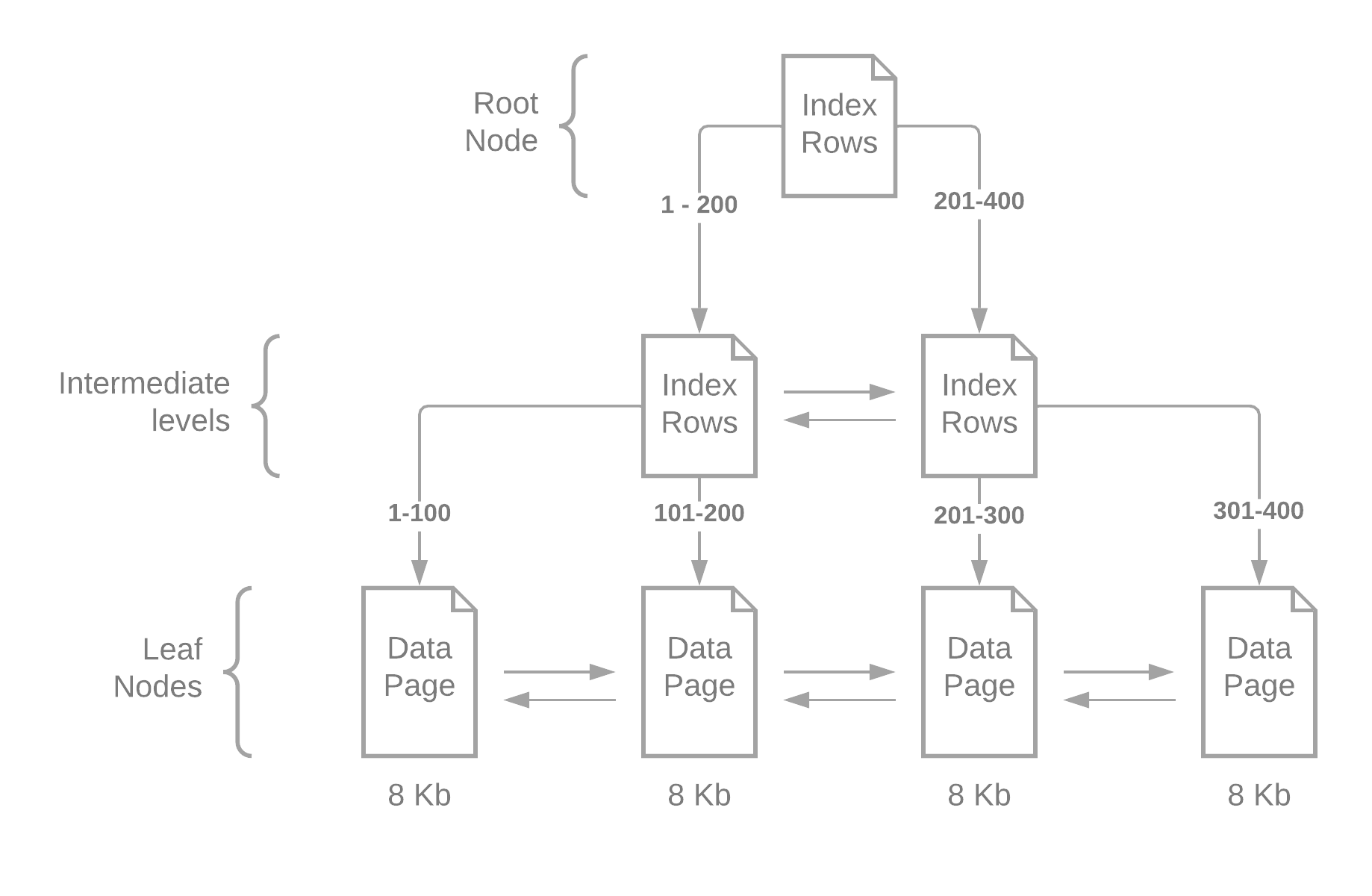
1 – B-Tree representation
This overview of the data structure is very high level, but if you want to go more in-depth, I would recommend this article from Geeks for Geeks: B-Tree.
OutSystems Automatic Indexing
Since indexes are an essential part of query performance, the OutSystems Platform automatically generates some indexes when creating entities.
By default, any entity will be a clustered index, meaning that we'll have the entire record on the leaf node of the ID index instead of a pointer. This type of index can be quite helpful for joins. However, this index can be deleted, turning our Entity into a heap. While this type of table has its uses, we will lose access to the platform CRUDs except for the Create<Entity> action.

2 – A heap in OutSystems
Additionally, whenever we add a foreign key to another Entity, the platform will default to Delete Rule Protect. When Protect or Delete are selected, an auto index is created. This is mandatory for the whole process of checking if the referred record can be deleted.
Indexing tradeoffs
So, now that we know how indexes help find records faster, why don’t we just index every field? Mainly due to two reasons: performance and disk space.
Every index requires disk and memory space, so it might be a good idea to discard unused indexes if storage is a concern.
Also, all indexes will need to be updated whenever a new record is inserted or deleted. Similarly, when updating a field included in an index, the index will also need to be updated. These actions might lead to some rebalancing of the tree, increasing the time to perform the transaction.
For example, if the Entity requires fast writing but reading speed is not a concern (example: logs), it might be good to remove the indexes applied automatically and turn the Entity into a Heap. Since the delete rules of Protect and Delete make the index mandatory, it might be better to set the rule to Ignore on the fields that are not commonly used in joins (this is now one of the OutSystems recommendations for data model best practices: OutSystems Guidelines). An example of this is the audit fields which will only be used if an audit is necessary.
Cardinality and table size impacts
Keeping in mind the structure of the B-Tree, we can deduce some cases where the index might not be needed. Traversing the tree to find a value is not free. Sometimes, indexes can result in more I/O operations (read/write) that have inherent costs, so in some scenarios, a table scan might actually be the best option.
One of these scenarios is when dealing with tables with few records—going through the tree and then accessing the file where the pointer is set to will take longer than for the database engine to go over the few rows and find it. In these cases, the query optimizer will usually ignore the index, so we will have the costs of maintaining it without the benefit.
Another case is the cardinality of the indexed column. If a column has few possible values (low cardinality), filtering by that value most likely will result in a significant portion of the whole table. Even having the double linked list to fetch all the values, the leaf nodes do not contain the entire row, so it might be faster for the engine to sort the original table or even go row by row.
Wildcard characters impact on index usage
Another consequence of a usual index structure is the effect of wildcard characters in searches. Considering the navigation on a char-based index, the position of our wildcard chars can actually cause an index to be ignored by the database. Let’s take as an example an index for country_name.
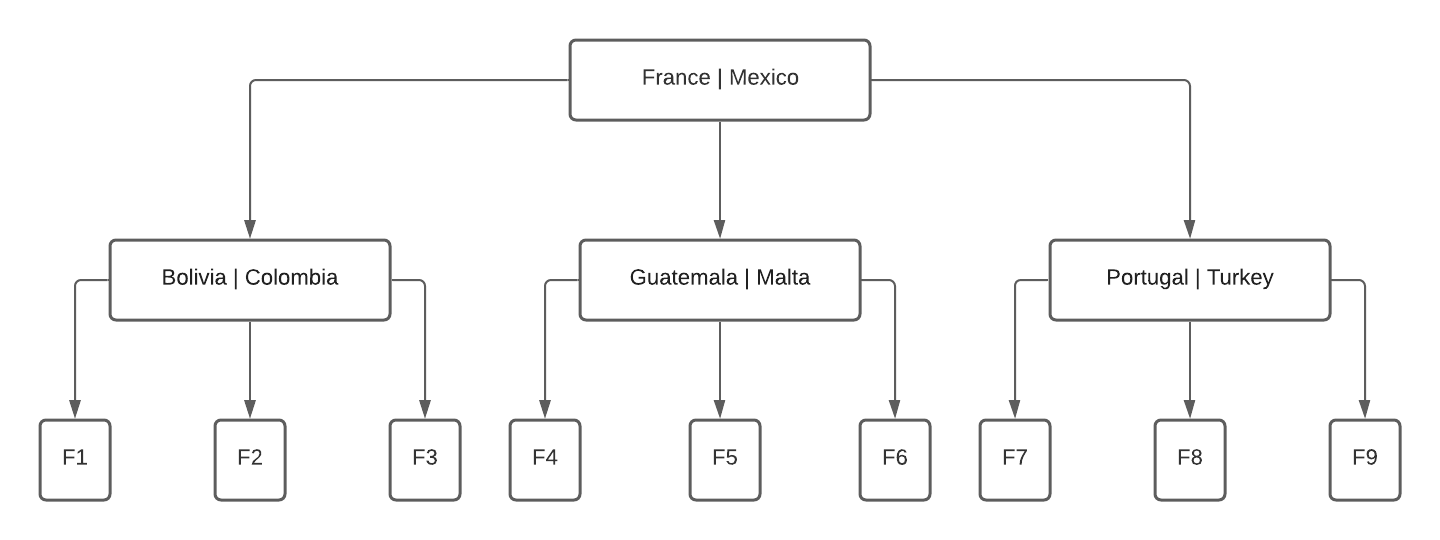
3 – Varchar index example
Suppose our query uses a WHERE country_name like ‘Italy’; as per image 3, the index will know in 2 steps that our value lies in the file F5 (Since Italy will be between Guatemala and Malta when sorting alphabetically). Similarly, if we change the WHERE clause to country_name like ‘It%’, the database can find the first record and just keep traversing the list until the condition is no longer true. However, if we use in our WHERE clause ‘%italy’, the sort becomes unusable.
One common scenario where removing the leading wildcard character can lead to performance enhancements is when we have a unique alphanumeric identifier. Since they are unique, they are prime candidates for indexing. So if the users search by that field often and it is a value that they are familiar with, removing the wildcard from the beginning might be a good step in optimizing your query.
Composite Indexes
The most common types of indexes are the ones that use only one column, but we can create indexes with several columns. These types of indexes are called composite indexes. These indexes are pretty good if you have WHERE clauses that use all or some of its columns. However, there are a few things to keep in mind.
If we think about our B-Tree and the wildcard search, we can infer that order matters. When sorting the data, the database will sort by the order the attributes are selected.
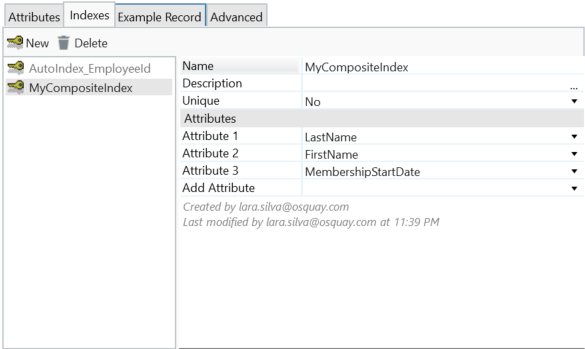
4 – A composite index in OutSystems
Given the example in image 4, our index will be sorted by LastName, then First Name, and then Membership Start date. So, if we search for FirstName = ‘John’, the sort becomes irrelevant. However, if we search for LastName = ‘Doe’ AND FirstName = ‘John’, then the database engine will be able to use it.
SQLShack has a great article about this topic with some examples and execution plans: SQLShack Article.
Index only access – covering indexes
In an edge case of composite indexes, a covering index is an index that has all the columns that we need for a particular query. This index has the advantage that there's no need to access the rows that contain the data we need since the values live on the index itself. Using the index from the example above and taking into consideration a query like the following:
SELECT FirstName, LastName
FROM Demo
WHERE MembershipStartDate > ‘2021-01-01’
The database engine would not need to access the rows since all three fields are in the index. This can increase our performance a lot. However, this index is quite limiting in its use cases. If we change that query to select or filter by a column not included in our index, the database engine will need to reaccess the table to load that column.
If you want to read more about covering indexes, this is a great article: Use the Index Luke - Covering Indexes.
Indexing outside of the platform
Sometimes changing our queries or using the indexes that OutSystems offers out of the box might not be enough to solve our performance issues. Maybe we have to perform searches on a large text field (text index), or you have to search locations by proximity (spatial index). In those cases, we can use more specific indexes provided by the database that OutSystems do not directly support.
We should avoid using the platform reserved prefix 'OSIDX_' when doing this. We should also consider that since the platform does not control these indexes, the DBA will need to recreate them in the other environments of your infrastructure. You can check OutSystems' documentation here: Outsystems documentation - Database Indexes.
This article goes over several possible optimizations and usages of indexes. Still, the OutSystems Platform already does a lot of the work automatically. But when those complex and heavy queries are necessary, I hope this information comes in handy.
Indexes and databases, in general, are a fascinating topic, but in this article, we barely skimmed the surface. I hope this has sparked your interest in this fantastic subject.
If you want to read more about indexes, here is a list of some of the great resources I have found during my research:
Like this article? Share it:



